In 2016, the World Economic Forum claimed we are experiencing the fourth wave of the Industrial Revolution: automation using cyber-physical systems. Key elements of this wave include machine intelligence, blockchain-based decentralized governance, and genome editing. As has been the case with previous waves, these technologies reduce the need for human labor but pose new ethical challenges, especially for artificial intelligence development companies and their clients.
The purpose of this article is to review recent ideas on detecting and mitigating unwanted bias in machine learning models. We will discuss recently created guidelines around trustworthy AI, review examples of AI bias arising from both model choice and underlying societal bias, suggest business and technical practices to detect and mitigate biased AI, and discuss legal obligations as they currently exist under the GDPR and where they might develop in the future.
Humans: the ultimate source of bias in machine learning
All models are made by humans and reflect human biases. Machine learning models can reflect the biases of organizational teams, of the designers in those teams, the data scientists who implement the models, and the data engineers that gather data. Naturally, they also reflect the bias inherent in the data itself. Just as we expect a level of trustworthiness from human decision-makers, we should expect and deliver a level of trustworthiness from our models.
A trustworthy model will still contain many biases because bias (in its broadest sense) is the backbone of machine learning. A breast cancer prediction model will correctly predict that patients with a history of breast cancer are biased towards a positive result. Depending on the design, it may learn that women are biased towards a positive result. The final model may have different levels of accuracy for women and men, and be biased in that way. The key question to ask is not Is my model biased?, because the answer will always be yes.
Searching for better questions, the European Union High Level Expert Group on Artificial Intelligence has produced guidelines applicable to model building. In general, machine learning models should be:
- Lawful—respecting all applicable laws and regulations
- Ethical—respecting ethical principles and values
- Robust—both from a technical perspective while taking into account its social environment
These short requirements, and their longer form, include and go beyond issues of bias, acting as a checklist for engineers and teams. We can develop more trustworthy AI systems by examining those biases within our models that could be unlawful, unethical, or un-robust, in the context of the problem statement and domain.
Historical cases of AI bias
Below are three historical models with dubious trustworthiness, owing to AI bias that is unlawful, unethical, or un-robust. The first and most famous case, the COMPAS model, shows how even the simplest models can discriminate unethically according to race. The second case illustrates a flaw in most natural language processing (NLP) models: They are not robust to racial, sexual and other prejudices. The final case, the Allegheny Family Screening Tool, shows an example of a model fundamentally flawed by biased data, and some best practices in mitigating those flaws.
COMPAS
The canonical example of biased, untrustworthy AI is the COMPAS system, used in Florida and other states in the US. The COMPAS system used a regression model to predict whether or not a perpetrator was likely to recidivate. Though optimized for overall accuracy, the model predicted double the number of false positives for recidivism for African American ethnicities than for Caucasian ethnicities.
The COMPAS example shows how unwanted bias can creep into our models no matter how comfortable our methodology. From a technical perspective, the approach taken to COMPAS data was extremely ordinary, though the underlying survey data contained questions with questionable relevance. A small supervised model was trained on a dataset with a small number of features. (In my practice, I have followed a similar technical procedure dozens of times, as is likely the case for any data scientist or ML engineer.) Yet, ordinary design choices produced a model that contained unwanted, racially discriminatory bias.
The biggest issue in the COMPAS case was not with the simple model choice, or even that the data was flawed. Rather, the COMPAS team failed to consider that the domain (sentencing), the question (detecting recidivism), and the answers (recidivism scores) are known to involve disparities on racial, sexual, and other axes even when algorithms are not involved. Had the team looked for bias, they would have found it. With that awareness, the COMPAS team might have been able to test different approaches and recreate the model while adjusting for bias. This would have then worked to reduce unfair incarceration of African Americans, rather than exacerbating it.
Large, pre-trained models form the base for most NLP tasks. Unless these base models are specially designed to avoid bias along a particular axis, they are certain to be imbued with the inherent prejudices of the corpora they are trained with—for the same reason that these models work at all. The results of this bias, along racial and gendered lines, have been shown on Word2Vec and GloVe models trained on Common Crawl and Google News respectively. While contextual models such as BERT are the current state-of-the-art (rather than Word2Vec and GloVe), there is no evidence the corpora these models are trained on are any less discriminatory.
Although the best model architectures for any NLP problem are imbued with discriminatory sentiment, the solution is not to abandon pre-trained models but rather to consider the particular domain in question, the problem statement, and the data in totality with the team. If an application is one where discriminatory prejudice by humans is known to play a significant part, developers should be aware that models are likely to perpetuate that discrimination.
Allegheny family screening tool: unfairly biased, but well-designed and mitigated
In this final example, we discuss a model built from unfairly discriminatory data, but the unwanted bias is mitigated in several ways. The Allegheny Family Screening Tool is a model designed to assist humans in deciding whether a child should be removed from their family because of abusive circumstances. The tool was designed openly and transparently with public forums and opportunities to find flaws and inequities in the software.
The unwanted bias in the model stems from a public dataset that reflects broader societal prejudices. Middle- and upper-class families have a higher ability to “hide” abuse by using private health providers. Referrals to Allegheny County occur over three times as often for African-American and biracial families than white families. Commentators like Virginia Eubanks and Ellen Broad have claimed that data issues like these can only be fixed if society is fixed, a task beyond any single engineer.
In production, the county combats inequities in its model by using it only as an advisory tool for frontline workers, and designs training programs so that frontline workers are aware of the failings of the advisory model when they make their decisions. With new developments in debiasing algorithms, Allegheny County has new opportunities to mitigate latent bias in the model.
The development of the Allegheny tool has much to teach engineers about the limits of algorithms to overcome latent discrimination in data and the societal discrimination that underlies that data. It provides engineers and designers with an example of a consultative model building which can mitigate the real-world impact of potential discriminatory bias in a model.
Avoiding and mitigating AI bias: key business awareness
Fortunately, there are some debiasing approaches and methods—many of which use the COMPAS dataset as a benchmark.
Improve diversity, mitigate diversity deficits
Maintaining diverse teams, both in terms of demographics and in terms of skillsets, is important for avoiding and mitigating unwanted AI bias. Despite continuous lip service paid to diversity by tech executives, women and people of color remain under-represented.
Various ML models perform poorer on statistical minorities within the AI industry itself, and the people to first notice these issues are users who are female and/or people of color. With more diversity in AI teams, issues around unwanted bias can be noticed and mitigated before releasing into production.
Be aware of proxies: removing protected class labels from a model may not work!
A common, naïve approach to removing bias related to protected classes (such as sex or race) from data is to delete the labels marking race or sex from the models. In many cases, this will not work, because the model can build up understandings of these protected classes from other labels, such as postal codes. The usual practice involves removing these labels as well, both to improve the results of the models in production but also due to legal requirements. The recent development of debiasing algorithms, which we will discuss below, represents a way to mitigate AI bias without removing labels.
Be aware of technical limitations
Even the best practices in product design and model building will not be enough to remove the risks of unwanted bias, particularly in cases of biased data. It is important to recognize the limitations of our data, models, and technical solutions to bias, both for awareness’ sake, and so that human methods of limiting bias in machine learning such as human-in-the-loop can be considered.
Avoiding and mitigating AI bias: key technical tools for awareness and debiasing
Data scientists have a growing number of technical awareness and debiasing tools available to them, which supplement a team’s capacity to avoid and mitigate AI bias. Currently, awareness tools are more sophisticated and cover a wide range of model choices and bias measures, while debiasing tools are nascent and can mitigate bias in models only in specific cases.
Awareness and debiasing tools for supervised learning algorithms
IBM has released a suite of awareness and debiasing tools for binary classifiers under the AI Fairness project. To detect AI bias and mitigate against it, all methods require a class label (e.g., race, sexual orientation). Against this class label, a range of metrics can be run (e.g., disparate impact and equal opportunity difference) that quantify the model’s bias toward particular members of the class. We include an explanation of these metrics at the bottom of the article.
Once bias is detected, the AI Fairness 360 library (AIF360) has 10 debiasing approaches (and counting) that can be applied to models ranging from simple classifiers to deep neural networks. Some are preprocessing algorithms, which aim to balance the data itself. Others are in-processing algorithms which penalize unwanted bias while building the model. Yet others apply postprocessing steps to balance favorable outcomes after a prediction. The particular best choice will depend on your problem.
AIF360 has a significant practical limitation in that the bias detection and mitigation algorithms are designed for binary classification problems, and need to be extended to multiclass and regression problems. Other libraries, such as Aequitas and LIME, have good metrics for some more complicated models—but they only detect bias. They aren’t capable of fixing it. But even just the knowledge that a model is biased before it goes into production is still very useful, as it should lead to testing alternative approaches before release.
General awareness tool: LIME
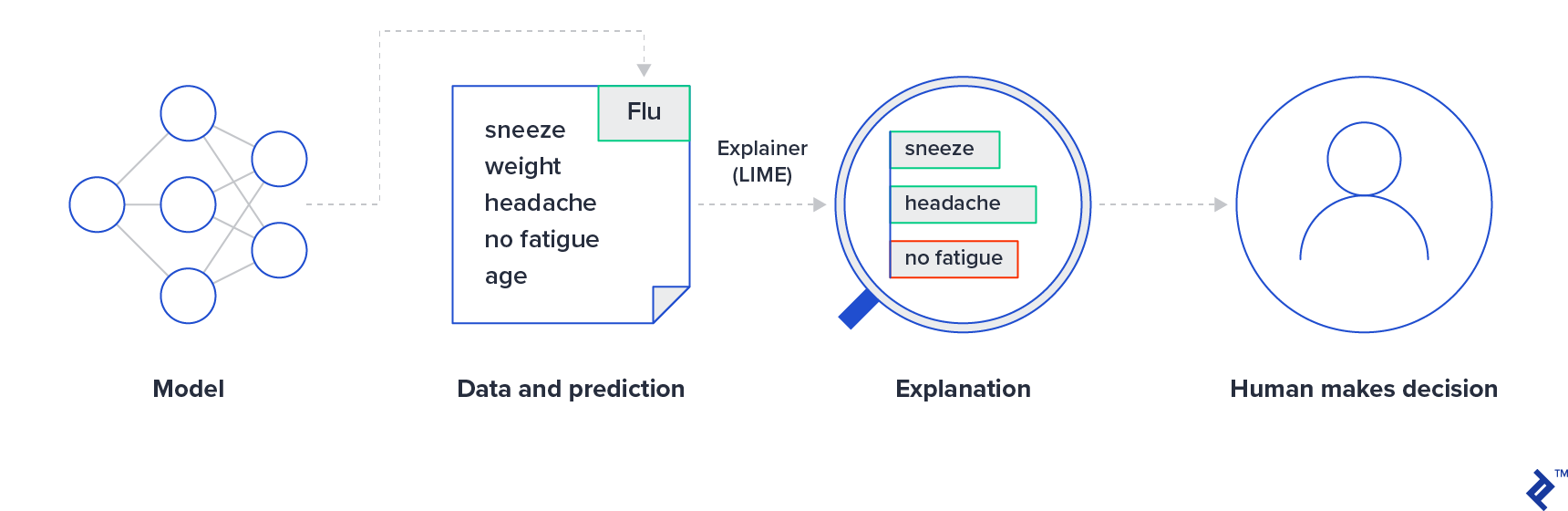
The Local Interpretable Model-agnostic Explanations (LIME) toolkit can be used to measure feature importance and explain the local behavior of most models—multiclass classification, regression, and deep learning applications included. The general idea is to fit a highly interpretable linear or tree-based model to the predictions of the model being tested for bias.
For instance, deep CNNs for image recognition are very powerful but not very interpretable. By training a linear model to emulate the behavior of the network, we can gain some insight into how it works. Optionally, human decision-makers can review the reasons behind the model’s decision in specific cases through LIME and make a final decision on top of that. This process in a medical context is demonstrated with the image below.
Debiasing NLP models
Earlier, we discussed the biases latent in most corpora used for training NLP models. If unwanted bias is likely to exist for a given problem, I recommend readily available debiased word embeddings. Judging from the interest from the academic community, it is likely that newer NLP models like BERT will have debiased word embeddings shortly.
Debiasing convolutional neural networks (CNNs)
Although LIME can explain the importance of individual features and provide local explanations of behavior on particular image inputs, LIME does not explain a CNN’s overall behavior or allow data scientists to search for unwanted bias.
In famous cases where unwanted CNN bias was found, members of the public (such as Joy Buolamwini) noticed instances of bias based on their membership of an underprivileged group. Hence the best approaches in mitigation combine technical and business approaches: Test often, and build diverse teams that can find unwanted AI bias through testing before production.
Legal obligations and future directions around AI ethics
In this section, we focus on the European Union’s General Data Protection Regulation (GDPR). The GDPR is globally the de facto standard in data protection legislation. (But it’s not the only legislation—there’s also China’s Personal Information Security Specification, for example.) The scope and meaning of the GDPR are highly debatable, so we’re not offering legal advice in this article, by any means. Nevertheless, it’s said that it’s in the interests of organizations globally to comply, as the GDPR applies not only to European organizations but any organizations handling data belonging to European citizens or residents.
The GDPR is separated into binding articles and non-binding recitals. While the articles impose some burdens on engineers and organizations using personal data, the most stringent provisions for bias mitigation are under Recital 71, and not binding. Recital 71 is among the most likely future regulations as it has already been contemplated by legislators. Commentaries explore GDPR obligations in further detail.
We will zoom in on two key requirements and what they mean for model builders.
1. Prevention of discriminatory effects
The GDPR imposes requirements on the technical approaches to any modeling on personal data. Data scientists working with sensitive personal data will want to read the text of Article 9, which forbids many uses of particularly sensitive personal data (such as racial identifiers). More general requirements can be found in Recital 71:
[. . .] use appropriate mathematical or statistical procedures, [. . .] ensure that the risk of errors is minimised [. . .], and prevent discriminatory effects on the basis of racial or ethnic origin, political opinion, religion or beliefs, trade union membership, genetic or health status, or sexual orientation.
GDPR (emphasis mine)
Much of this recital is accepted as fundamental to a good model building: Reducing the risk of errors is the first principle. However, under this recital, data scientists are obliged not only to create accurate models but models which do not discriminate! As outlined above, this may not be possible in all cases. The key remains to be sensitive to the discriminatory effects which might arise from the question at hand and its domain, using business and technical resources to detect and mitigate unwanted bias in AI models.
2. The right to an explanation
Rights to “meaningful information about the logic involved” in automated decision-making can be found throughout GDPR articles 13-15… Recital 71 explicitly calls for “the right […] to obtain an explanation” (emphasis mine) of automated decisions. (However, the debate continues as to the extent of any binding right to an explanation.)
As we have discussed, some tools for providing explanations for model behavior do exist, but complex models (such as those involving computer vision or NLP) cannot be easily made explainable without losing accuracy. Debate continues as to what an explanation would look like. As a minimum best practice, for models likely to be in use into 2020, LIME or other interpretation methods should be developed and tested for production.
Ethics and AI: a worthy and necessary challenge
In this post, we have reviewed the problems of unwanted bias in our models, discussed some historical examples, provided some guidelines for businesses and tools for technologists, and discussed key regulations relating to unwanted bias.
As the intelligence of machine learning models surpasses human intelligence, they also surpass human understanding. But, as long as models are designed by humans and trained on data gathered by humans, they will inherit human prejudices.
Managing these human prejudices requires careful attention to data, using AI to help detect and combat unwanted bias when necessary, building sufficiently diverse teams, and having a shared sense of empathy for the users and targets of a given problem space. Ensuring that AI is fair is a fundamental challenge of automation. As the humans and engineers behind that automation, it is our ethical and legal obligation to ensure AI acts as a force for fairness.
Further reading on AI ethics and bias in machine learning
Books on AI bias
- Made by Humans: The AI Condition
- Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor
- Digital Dead End: Fighting for Social Justice in the Information Age
Machine learning resources
- Interpretable Machine Learning: A Guide for Making Black Box Models Explainable
- IBM’s AI Fairness 360 Demo
AI bias organizations
- Algorithmic Justice League
- AINow Institute and their paper Discriminating Systems – Gender, Race, and Power in AI
Debiasing conference papers and journal articles
- Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
- AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias
- Machine Bias (Long-form journal article)
Definitions of AI bias metrics
Disparate impact
Disparate impact is defined as “the ratio in the probability of favorable outcomes between the unprivileged and privileged groups.” For instance, if women are 70% as likely to receive a perfect credit rating as men, this represents a disparate impact. The disparate impact may be present both in the training data and in the model’s predictions: in these cases, it is important to look deeper into the underlying training data and decide if disparate impact is acceptable or should be mitigated.
Equal Opportunity Difference
Equal opportunity difference is defined (in the AI Fairness 360 article found above) as “the difference in true positive rates [recall] between unprivileged and privileged groups.” The famous example discussed in the paper of high equal opportunity difference is the COMPAS case. As discussed above, African-Americans were being erroneously assessed as high-risk at a higher rate than Caucasian offenders. This discrepancy constitutes an equal opportunity difference.
Source: TheNextWeb