WHAT ARE BIG DATA PIPELINES
Imagine you run an online school like Rise Networks Data Science School, and you have thousands of transactions every minute. Captured data include ID numbers, age, the amount paid, registered courses, degree, location and maybe race etc all this data will definitely be stored in a database but to efficiently get insights from this data in the database it has to be moved in real-time to different processing and analytics applications.
Your online school might want to evaluate which department registers earlier for instance and replicate what triggers these early registrations in other use-cases to enable the desired result of early registrations across the board, hence this data can not just be seated in the database, it has to be processed and this is where The Big Data Pipeline comes into play!
WHAT IS A BIG DATA PIPELINE
The data pipeline defines how information moves from point A to point B, from collection to refinement, and from storage to analysis. It encompasses the complete data movement process, from data collection, such as on a device, to data movements, such as through data streams or batch processing, and data destination, such as a data lake or application.
The data pipeline delivers data to its destination in a fluid manner, allowing business to move smoothly. Quarterly reports may be missed, KPIs may be inaccurate, user behaviour may not be processed, ad income may be lost, and so on if the pipeline is clogged. An organization’s pipelines can be its lifeblood.
DATA PIPELINE COMPONENTS
Let’s look at what a data pipeline typically consists of to get a better understanding of how it works in general. According to David Wells, a senior research analyst at Eckerson Group, there are eight different sorts of data pipeline components. Let’s take a quick look at them.
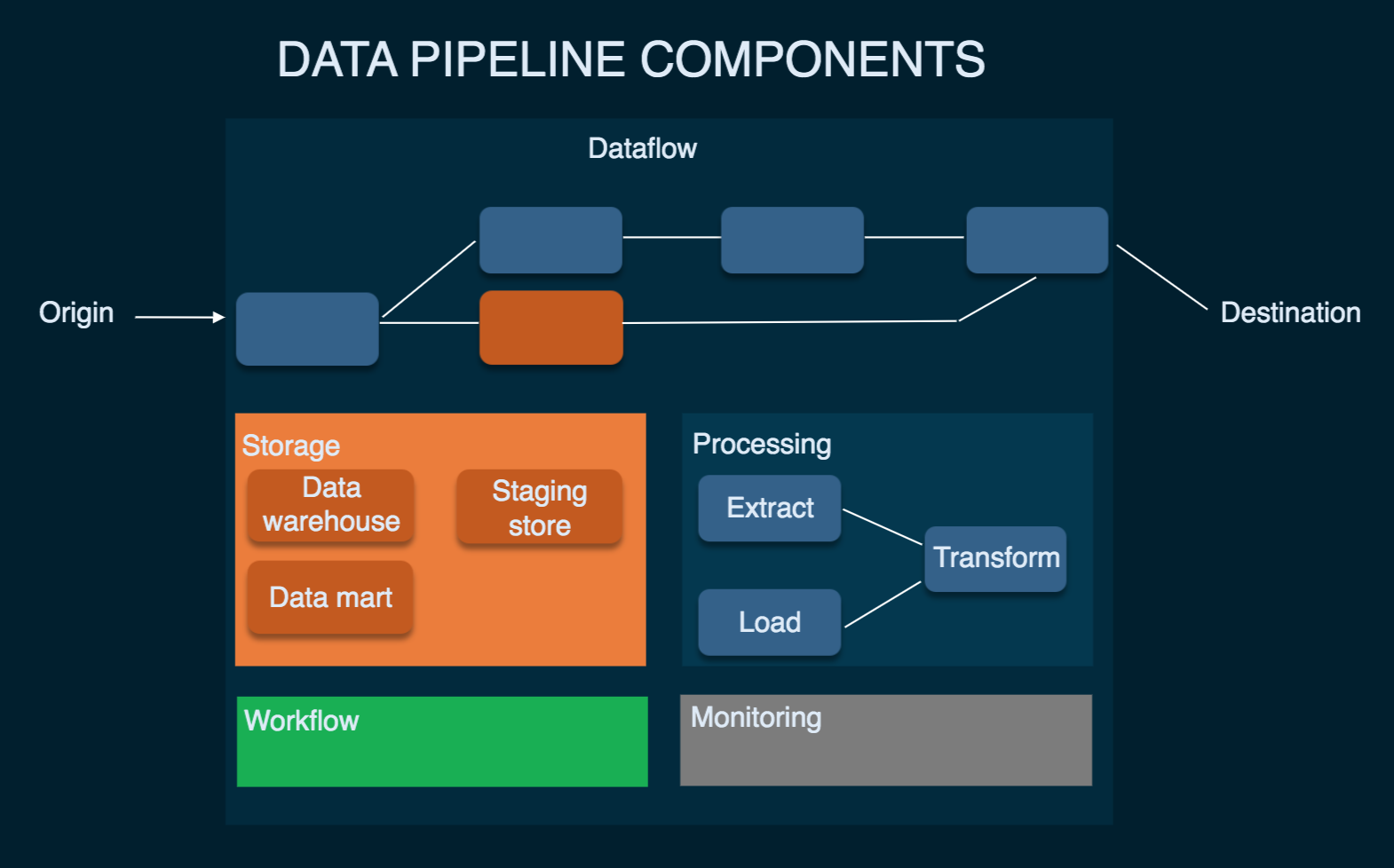
Data pipeline components. Picture source example: Eckerson Group
Origin
Origin is the point of data entry in a data pipeline. Data sources (transaction processing application, IoT device sensors, social media, application APIs, or any public datasets) and storage systems (data warehouse, data lake, or data lakehouse) of a company’s reporting and analytical data environment can be an origin.
Destination
The final point to which data is transferred is called a destination. Destination depends on a use case: Data can be sourced to power data visualization and analytical tools or moved to storage like a data lake or a data warehouse. We’ll get back to the types of storage a bit later.
Dataflow
That’s the movement of data from origin to destination, including the changes it undergoes along the way as well as the data stores it goes through. One of the approaches to dataflow is called ETL, which stands for extract, transform, and load:
Extract – getting/ingesting data from original, disparate source systems.
Transform – moving data in temporary storage known as a staging area. Transforming data to ensure it meets agreed formats for further uses, such as analysis.
Load – loading reformatted data to the final storage destination.
Storage
Storage refers to systems where data is preserved at different stages as it moves through the pipeline. Data storage choices depend on various factors, for example, the volume of data and frequency and volume of queries to a storage system uses of data, etc. (think of the online bookstore example).
Processing
Processing includes activities and steps for ingesting data from sources, storing it, transforming it, and delivering it to a destination. While data processing is related to data flow, it focuses on how to implement this movement.
Workflow
The workflow defines a sequence of processes (tasks) and their dependence on each other in a data pipeline. Knowing several concepts – jobs, upstream, and downstream – would help you here. A job is a unit of work or execution that performs specified work – what is being done to data in this case. Upstream means a source from which data enters a pipeline, while downstream means a destination it goes to. Data, like water, flows down the data pipeline. Also, upstream jobs are the ones that must be successfully executed before the next ones – downstream – can begin.
Monitoring
The goal of monitoring is to check how the data pipeline and its stages are working: whether it remains efficient with growing data load, data remains accurate and consistent as it goes through processing stages, or whether no data is lost along the way.
Technology
These are tools and infrastructure behind data flow, storage, processing, workflow, and monitoring. Tooling and infrastructure options depend on many factors, such as organization size and industry, data volumes, use cases for data, budget, security requirements, etc. Some of the building blocks for data pipelines are:
ETL tools, including data preparation and data integration tools (Informatica Power Center, Apache Spark, Talend Open Studio).
data warehouses – central repositories for relational data transformed (processed) for a particular purpose (Amazon Redshift, Snowflake, Oracle). Since the main users are business professionals, a common use case for data warehouses is business intelligence.
data lakes – storages for raw, both relational and non-relational data (Microsoft Azure, IBM). Data lakes are mostly used by data scientists for machine learning projects.
FEATURES THAT DETERMINE IF YOUR BUSINESS NEEDS DATA PIPELINES.
Not every company needs a big data pipeline, and not every application necessitates the use of a pipeline. The features of data pipelines are unique. Features such as these may necessitate the use of a data pipeline:
Large data sets in need of storage
Collect information from a variety of places.
Data needed to be stored in the cloud.
For analysis or reporting, and in need of fast access.
Each major cloud provider has its own set of tools to assist with the creation of a data pipeline.