This post explores three tricks that can be used for data science that can help solve real problems for customer support. Two for natural language processing in a customer support context and one for identifying attack Internet attack traffic.
Through these examples, we hope to demonstrate how invaluable data processing tricks, visualisations and tools can be before putting data into a machine learning algorithm. By refining data prior to processing, we are able to achieve dramatically improved results without needing to change the underlying machine learning strategies which are used.
Know the Limits (Language Classification)
When browsing a social media site, you may find the site prompts you to translate a post even though it is in your language.
We recently came across a similar problem at Cloudflare when we were looking into language classification for chat support messages. Using an off-the-shelf classification algorithm, users with short messages often had their chats classified incorrectly and our analysis found there’s a correlation between the length of a message and the accuracy of the classification (based on the browser Accept-Language header and the languages of the country where the request was submitted):
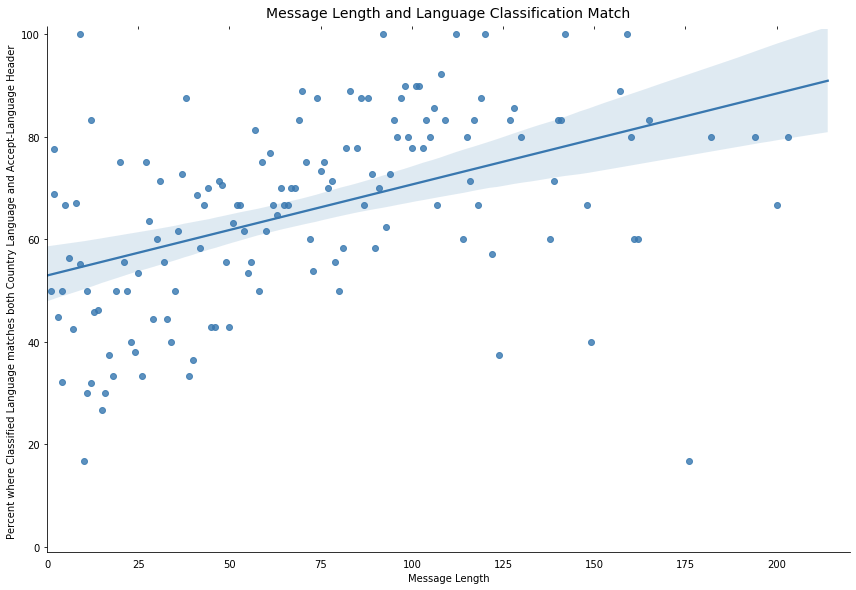
On a subset of tickets, comparing the classified language against the web browser Accept-Language header, we found there was broad agreement between these two properties. When we considered the languages associated with the user’s country, we found another signal.
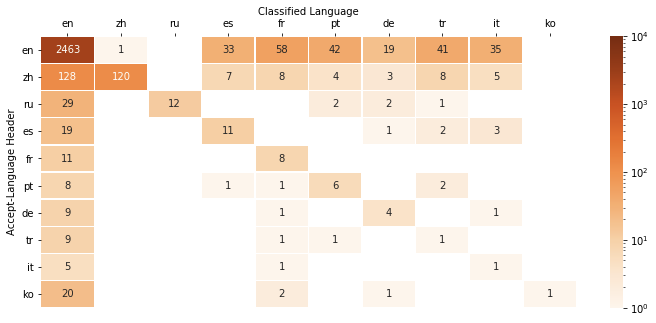
In 67% of our sample, we found agreement between these three signals. In 15% of instances the classified language agreed with only the Accept-Language header and in 5% of cases there was only agreement with the languages associated with the user’s country.
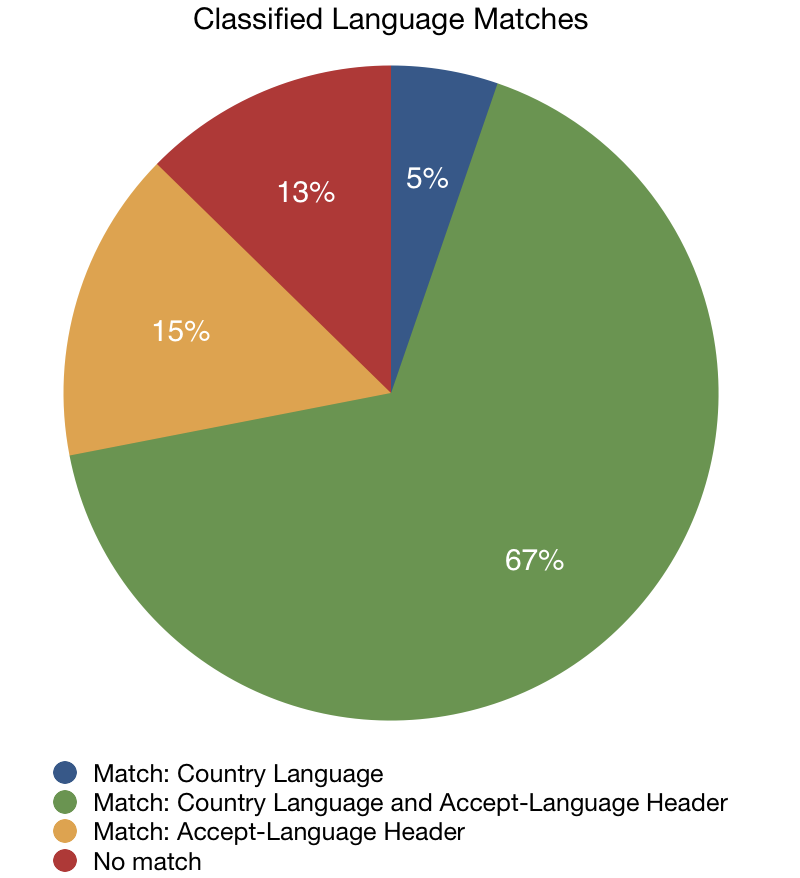
We decided the ideal approach was to train a machine learning model that would take all three signals (plus the confidence rate from the language classification algorithm) and use that to make a prediction. By knowing the limits of a given classification algorithm, we were able to develop an approach that helped compliment it.
A naive approach to do the same may not even need a trained model to do so, simply requiring agreement between two of three properties (classified language, Accept-Language header and country header) helps make a decision about the right language to use.
Hold Your Fire (Fuzzy String Matching)
Fuzzy String Matching is often used in natural language processing when trying to extract information from human text. For example, this can be used for extracting error messages from customer support tickets to do automatic classification. At Cloudflare, we use this as one signal in our natural language processing pipeline for support tickets.
Engineers often use the Levenshtein distance algorithm for string matching; for example, this algorithm is implemented in the Python fuzzywuzzy library. This approach has a high computational overhead (for two strings of length k and l, the algorithm runs in O(k * l) time).
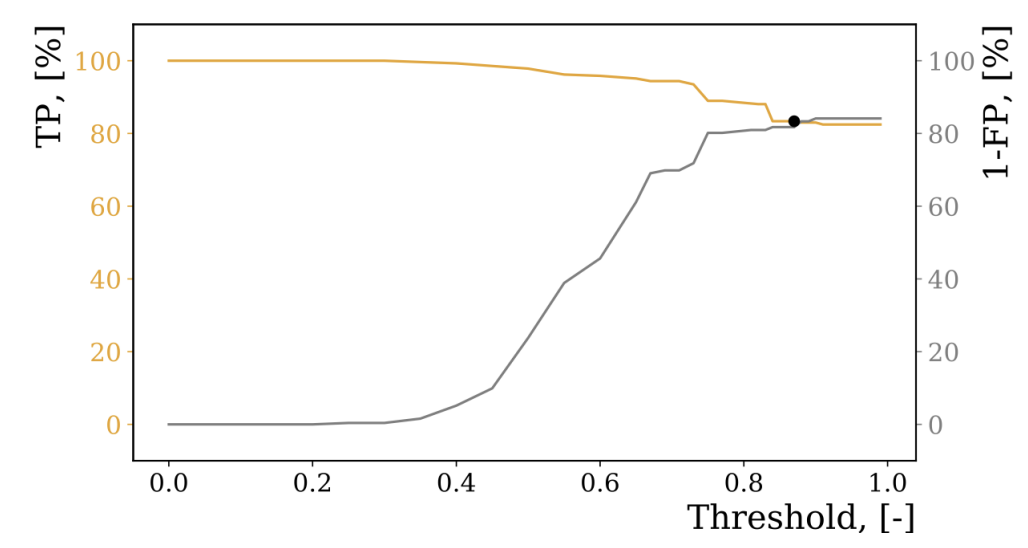
To understand the performance of different string matching algorithms in a customer support context, we compared multiple algorithms (Cosine, Dice, Damerau, LCS and Levenshtein) and measured the true positive rate (TP), false positive rate (FP) and the ratio of false positives to true positives (FP/TP).
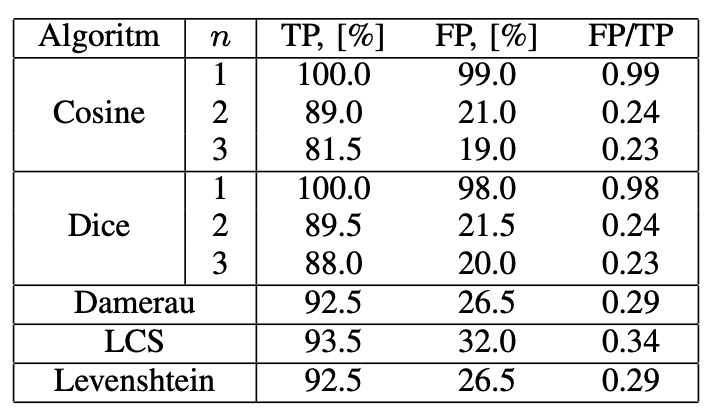
We opted for the Cosine algorithm, not just because it outperformed the Levenshtein algorithm, but also the computational difficulty was reduced to O(k + l) time. The Cosine similarity algorithm is a very simple algorithm; it works by representing words or phrases as a vector representation in a multidimensional vector space, where each unique letter of an alphabet is a separate dimension. The smaller the angle between the two vectors, the closer the word is to another.
The mathematical definitions of each string similarity algorithm and a scientific comparison can be found in our paper: M. Pikies and J. Ali, “String similarity algorithms for a ticket classification system,” 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 2019, pp. 36-41. https://doi.org/10.1109/CoDIT.2019.8820497
There were other optimisations we introduce to the fuzzy string matching approaches; the similarity threshold is determined by evaluating the True Positive and False Positive rates on various sample data. We further devised a new tokenization approach for handling phrases and numeric strings whilst using the FastText natural language processing library to determine candidate values for fuzzy string matching and to improve overall accuracy, we will share more about these optimisations in a further blog post.
“Beyond it is Another Dimension” (Threat Identification)
Attack alerting is particularly important at Cloudflare – this is useful for both monitoring the overall status of our network and providing proactive support to particular at-risk customers.
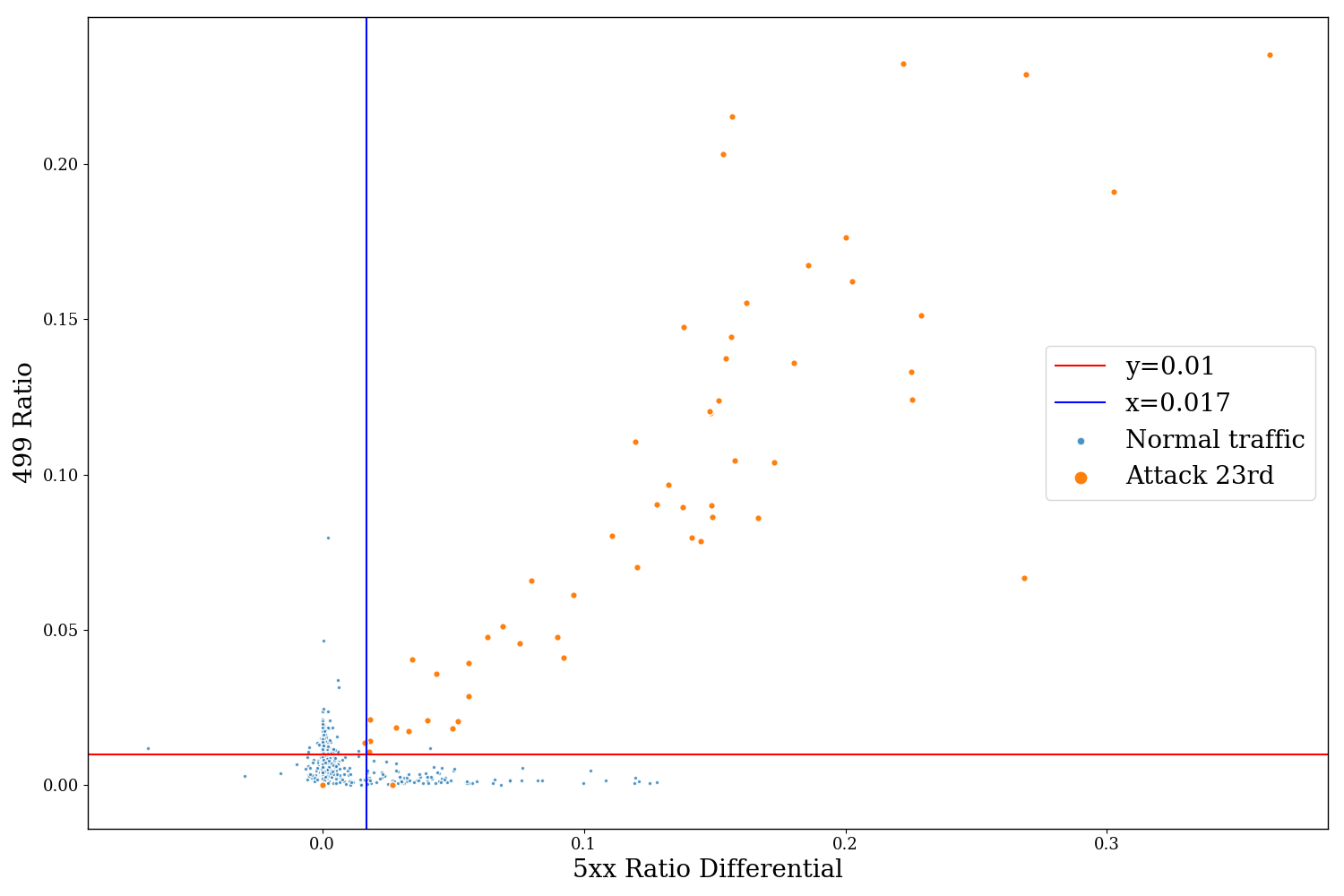
DDoS attacks can be represented in granularity by a few different features; including differences in request or error rates over a temporal baseline, the relationship between errors and request volumes and other metrics that indicate attack behaviour. One example of a metric we use to differentiate between whether a customer is under a low volume attack or they are experiencing another issue is the relationship between 499 error codes vs 5xx HTTP status codes. Cloudflare’s network edge returns a 499 status code when the client disconnects before the origin web server has an opportunity to respond, whilst 5xx status codes indicate an error handling the request. In the chart below; the x-axis measures the differential increase in 5xx errors over a baseline, whilst the y-axis represents the rate of 499 responses (each scatter represents a 15 minute interval). During a DDoS attack we notice a linear correlation between these criteria, whilst origin issues typically have an increase in one metric instead of another:
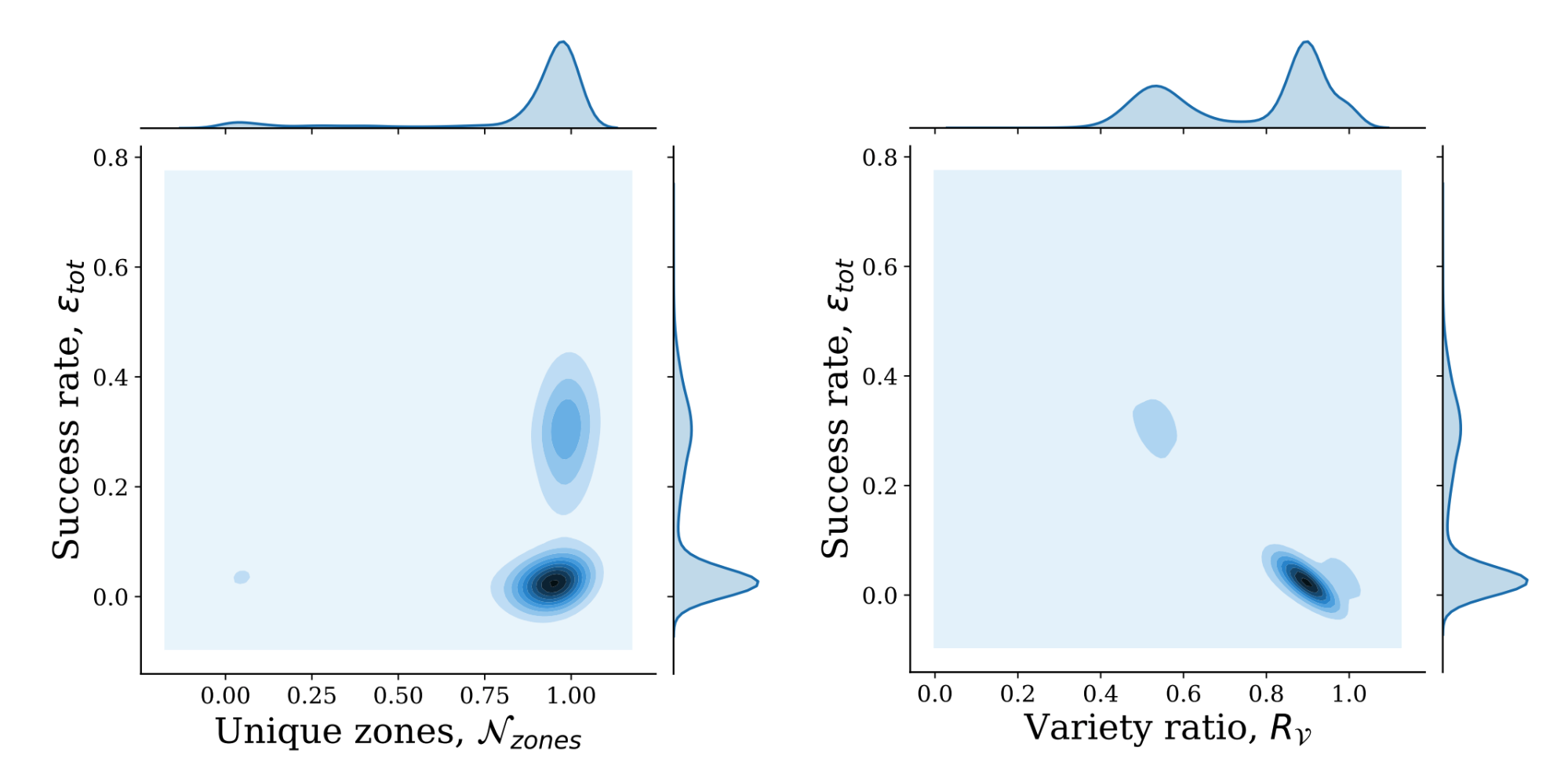
The next question is how this data can be used in more complicated situations – take the following example of identifying a credential stuffing attack in aggregate. We looked at a small number of anonymised data fields for the most prolific attackers of WordPress login portals. The data is based purely on HTTP headers, in total we saw 820 unique IPs towards 16,248 distinct zones (the IPs were hashed and requests were placed into “buckets” as they were collected). As WordPress returns a HTTP 200 when a login fails and a HTTP 302 on a successful login (redirecting to the login panel), we’re able to analyse this just from the status code returned.
On the left hand chart, the x-axis represents a normalised number of unique zones that are under attack (0 means the attacker is hitting the same site whilst 1 means the attacker is hitting all different sites) and the y-axis represents the success rate (using HTTP status codes, identifying the chance of a successful login). The right hand side chart switches the x-axis out for something called the “variety ratio” – this measures the rate of abnormal 4xx/5xx HTTP status codes (i.e. firewall blocks, rate limiting HTTP headers or 5xx status codes). We see clear clusters on both charts:
However, by plotting this chart in three dimensions with all three fields represented – clusters appear. These clusters are then grouped using an unsupervised clustering algorithm (agglomerative hierarchical clustering):
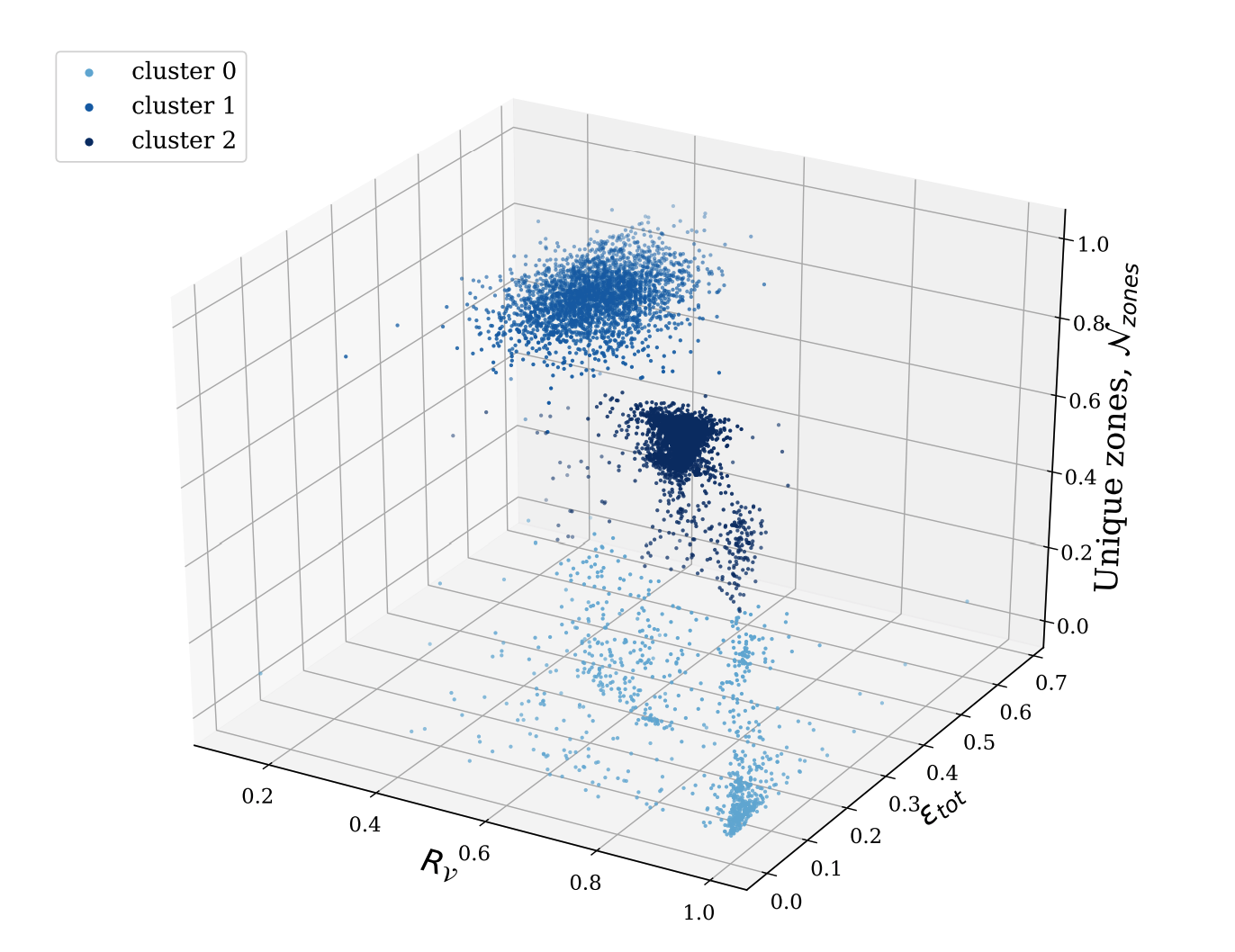
Cluster 1 has 99.45% of requests from the same country and 99.45% from the same User-Agent. This tactic, however, has advantages when looking at other clusters – for example, Cluster 0 had 89% of requests coming from three User-Agents (75%, 12.3% and 1.7%, respectively). By using this approach we are able to correlate such attacks together even when they would be hard to identify on a request-to-request basis (as they are being made from different IPs and with different request headers). Such strategies allow us to fingerprint attacks regardless of whether attackers are continuously changing how they make these requests to us.
By aggregating data together then representing the data in multiple dimensions, we are able to gain visibility into the data that would ordinarily not be possible on a request-to-request basis. In product level functionality, it is often important to make decisions on a signal-to-signal basis (“should this request be challenged whilst this one is allowed?”) but by looking at the data in aggregate we are able to focus on the interesting clusters and provide alerting systems which identify anomalies. Performing this in multiple dimensions provides the tools to reduce false positives dramatically.
Conclusion
From natural language processing to intelligent threat fingerprinting, using data science techniques has improved our ability to build new functionality. Recently, new machine learning approaches and strategies have been designed to process this data more efficiently and effectively; however, preprocessing of data remains a vital tool for doing this. When seeking to optimise data processing pipelines, it often helps to look not just at the tools being used, but also the input and structure of the data you seek to process.
Source: Cloudfare